本文共 1576 字,大约阅读时间需要 5 分钟。
迁移学习概述
在深度学习领域,通过预训练模型作为检查点开始训练生成神经网络模型实现对新任务的支持,这种方法通常被称为迁移学习,它的好处是不用再重头开始设计与训练一个全新的网络,而是基于已经训练好的网络模型,在其基础上进行参数与知识迁移,只需要很少量的计算资源开销与训练时间就可以实现对新任务的支持。
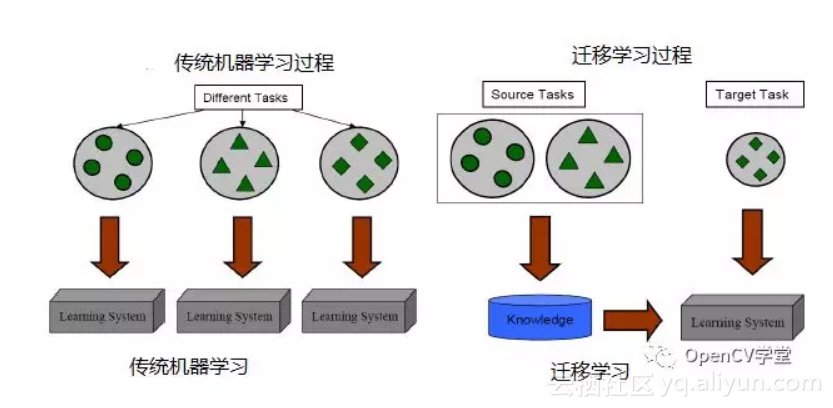
要理解迁移学习的整个过程就是要搞清楚下面三件事:
-
迁移学习迁移什么
-
迁移学习是怎么迁移的
-
迁移学习什么时候使用
迁移什么
在预训练模型中存在各种特征数据与权重信息、有些是与分类识别的对象本身关联比较紧密的特征数据与权重信息,有些是一些比较共性的特征数据与信息,是可以被不同的任务或者对象之间共享的,迁移学习就是要迁移那些共性特征数据与信息,从而避免再次学习这些知识,实现快速学习。简单点说迁移学习主要是实现卷积层共性特征迁移,
怎么迁移
迁移学习早期也被称为感应迁移(inductive transfer),为了搞清楚,迁移学习到底是怎么迁移的,大神Yoshua Bengio等人尝试定义了一个八层的神经网络,将ImageNet的数据集1000个种类分为A与B两个分类子集,数量均为500,然后继续分别训练生成forzen推断图、然后分别将网络模型A与B的前三层分别copy给没有训练之前网络B,并对B的余下5层随机初始化之后开始训练这两个全新的网络(B3B与A3B),他们想通过这个实验证明、如果B3B与A3B跟之前训练好的网络B有同样的识别准确率就说明自迁移网络B3B与迁移网络A3B的前三层网络特征是共性特征信息,可以用来迁移,如果网络性能下降则说明它们含有目标对象相关的个性特征无法用来迁移。
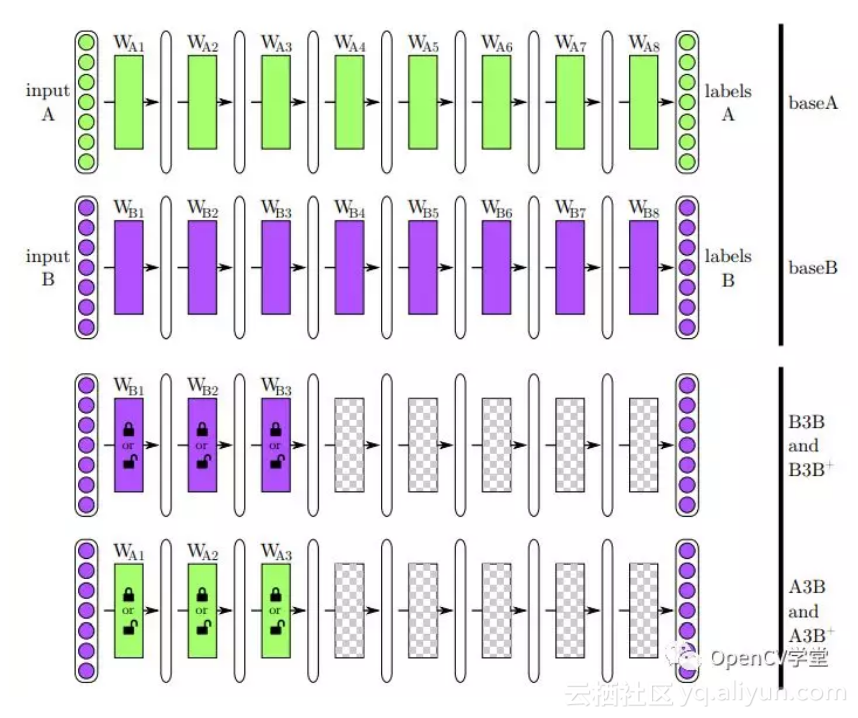
最终的实验结果表明,前面7层都是共性特征,只有网络的最后一层才是任务相关的个性特征数据,无法进行迁移,整个实验结果如下:
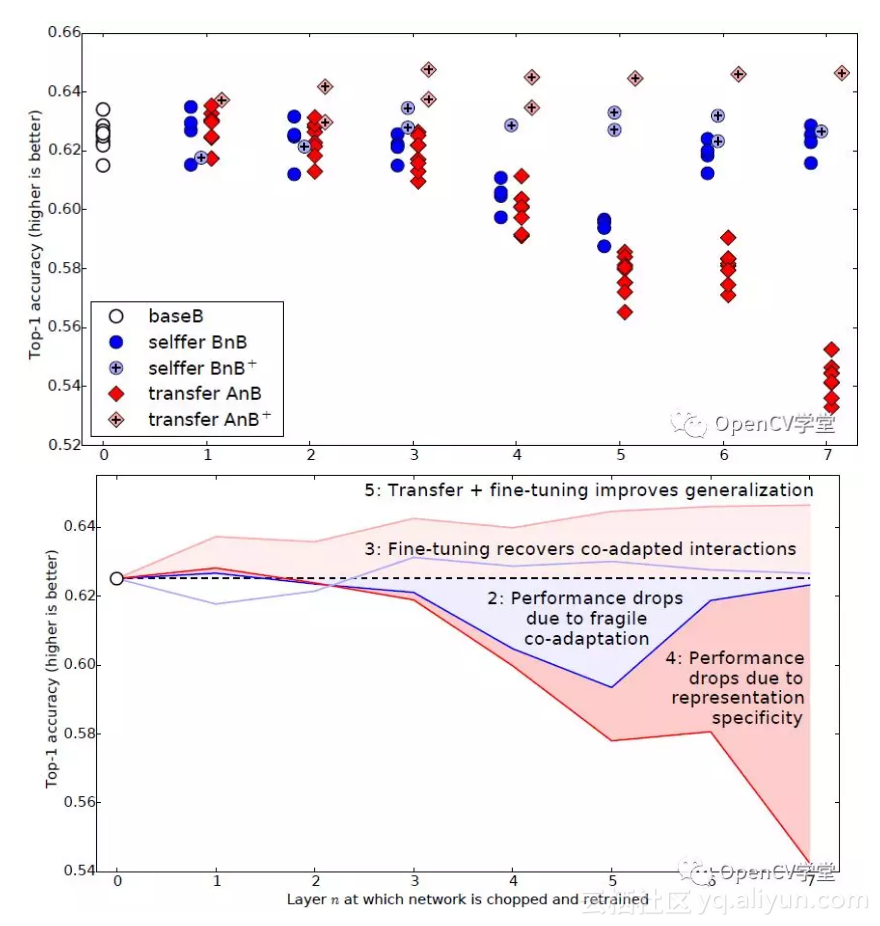
从上面可以看出单纯的迁移学习AnB的方式,随着层数的增加网络性能不断下降,但是通过迁移学习加fine-tuning的方式AnB+对前N层进行重新训练调整优化,迁移学习的效果居然比原来的还要好。充分说明迁移学习+fine-tuning是个训练卷积神经网络的好方法。
什么时候使用迁移
当我们有相似的任务需要完成的时候,我们可以使用预训练的相关模型,在此基础上进行迁移学习即可,这个方面caffe与tensorflow都提供大量的可以用于迁移学习的预训练模型库,在github上地址分别如下:
# Caffe模型 https://github.com/BVLC/caffe/wiki/Model-Zoo # tensorflow模型 https://github.com/tensorflow/models
在实际使用中我们把预训练的网络称为base-network,把要迁移的前n层复制到一个到目标网络(target network),然后随机初始化目标网络的余下各层、开始训练进行反向传播、反向传播时候有两种方法可以使用:
-
把前面n层冻结forzen、只对后面的层进行训练,这种方法适合少的样本数据,而且随着层冻结n数值增大、网络性能会下降,这种是单纯的迁移学习。
-
不冻结前n层、全程参与训练不断调整它们的参数,实现更好的网络性能这种方法称为迁移学习+fine-tuning
迁移学习使用
在tensorflow中通过tensorflow object detection API框架使用迁移学习是对象检测与识别,只需要几步即可:下面是我自己实现的基于tensorflow object detection API使用SSD模型迁移学习实现了简单的手势识别看视频即可:
转载地址:http://aszox.baihongyu.com/